-
[머신러닝] Large Language Model (LLM) 이란? 수학적인 내용을 말로인공지능/머신러닝 2025. 2. 26. 08:39반응형
LLM 모델은 기본적으로 단어들이나 문장들이 나올 가능성을 계산하는 시스템이에요. 이 모델은 엄청난 양의 텍스트를 보고, 어떤 단어가 어떤 상황에서 다음에 나올지 확률적으로 예측하도록 훈련됩니다. 예를 들어, "나는 매일 아침"이라는 말이 주어지면, 다음 단어로 "책을"이나 "운동을" 같은 게 나올 가능성을 숫자로 따져서 가장 그럴듯한 걸 골라내는 식이죠.
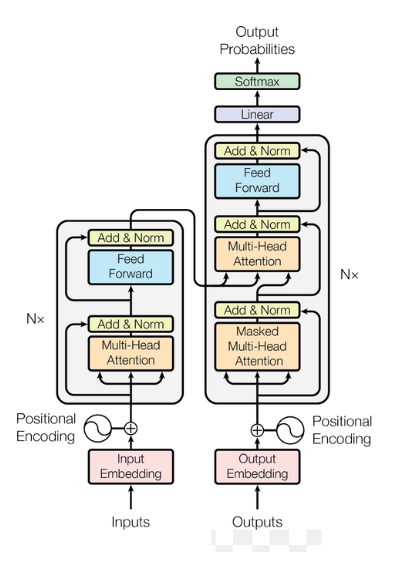
이 예측을 가능하게 하는 핵심 구조는 트랜스포머라는 방식인데, 이건 문장에서 단어들이 서로 얼마나 중요한지 가중치를 주는 방식으로 작동합니다. 문맥을 보면서, 멀리 떨어진 단어와 가까운 단어 중 어디에 더 신경을 써야 할지 판단하는 거예요. 이 과정에서 모델은 단어들을 숫자 벡터로 바꾸고, 그 벡터들 사이의 관계를 계산해서 어떤 단어가 다음에 올지 결정합니다.

학습할 때는 이 모델이 예측한 단어와 실제 데이터에서 나온 단어를 비교하면서 틀린 정도를 줄이려고 합니다. 이 틀린 정도를 측정하는 기준을 최소화하도록 계속 조정하는 거예요. 조정할 때는 미세한 변화로 모델의 내부 값을 조금씩 업데이트하는데, 이 과정이 수십억 번 반복되면서 점점 더 정확해지는 겁니다. 이 과정에서 모델이 가진 조정 가능한 값, 그러니까 파라미터가 수십억 개에 달하기 때문에 "라지"라는 이름이 붙은 거고요.
텍스트를 만들어낼 때는 이 예측한 가능성을 바탕으로 단어를 하나씩 뽑아내는 과정을 거칩니다. 가장 가능성이 높은 단어만 뽑을 수도 있고, 상위 몇 개 중에서 랜덤으로 고를 수도 있어요. 이렇게 하면 문장이 자연스럽게 이어지면서도 약간의 창의성을 발휘할 수 있습니다.

하지만 한계도 있어요. 모델이 예측하는 가능성은 학습 데이터에 크게 의존하기 때문에, 데이터에 없는 상황에서는 엉뚱한 결과를 내놓을 가능성이 있습니다. 또 데이터가 편향되어 있으면 그 편향된 방향으로 예측이 쏠릴 수도 있고요. 이런 문제를 줄이려면 학습 데이터를 더 다양하게 만들거나, 예측이 너무 한쪽으로 치우치지 않게 조정하는 방법을 써야 합니다.
반응형'인공지능 > 머신러닝' 카테고리의 다른 글
[머신러닝] 생성형 AI란? (2) 2025.02.26 [머신러닝] 멀티-헤드 어텐션(multi-head attention) 이란? (0) 2025.02.26 [머신러닝] 잔차 연결(residual connection) 이란? (0) 2025.02.26 [머신러닝] LLM에서 트랜스포머(Transformer)에 대해서 쉽게 말로 설명하면? (0) 2025.02.26 [머신러닝 이야기] 디지털 트윈(Digital Twin)이란? (0) 2025.02.26