-
[데이터 마이닝] Min-Hashing 란?인공지능/데이터 마이닝 2021. 2. 7. 16:31반응형
이번 포스팅에서는 데이터 마이닝 기법 중 Min-Hashing 알고리즘에 대해서 알아보겠다.
Min-Hashing 란?
Min-hashing 알고리즘은 데이터의 차원을 줄여서 줄어든 차원의 정보 만으로 클러스터링 하였을 때 본래 데이터의 클러스터링 결과와 거의 비슷하도록 하는 것으로, 본래 데이터의 차원이 너무 많거나, 샘플의 수가 너무 많을 때 사용된다. 즉, 빅 데이터 분석 시, 계산 시간과 로드를 줄여주고 필요한 클러스터링만 진행 하기 위한 암호화 방법이다.
직관적 이해
Min-hashing의 암호화 방법을 보다 명확하게 이해하기 위해서 간단한 예제를 설명해보겠다. 우선 아래와 같은 인풋 행렬이 있다고 하자. 이 행렬에서는 열과 행으로 된 어떠한 값이 있다. Min-hashing에서는 기본적으로 바이너리 데이터를 입력으로 사용한다.
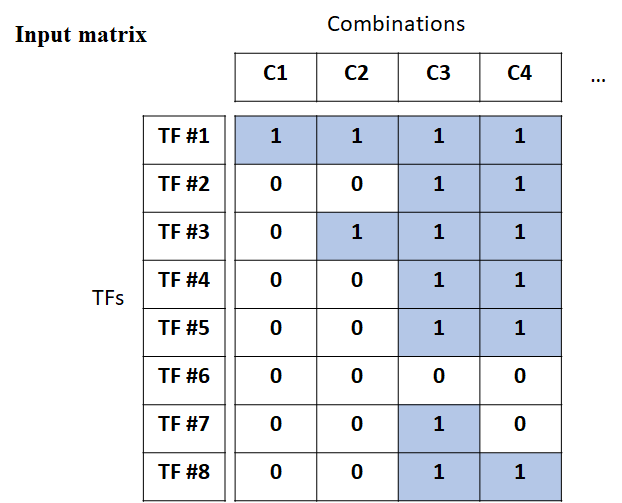
위의 인풋에서 행과 열은 본인의 데이터의 형태에 따라 어떠한 것도 될 수 있다. 여기서는 생물 데이터의 TF정보와 그에 따른 Combination을 행과 열로 설정하였다.
그러면 단계 별로 Min-Hashing 알고리즘이 작동하는 원리를 이해보도록 하자.
1 단계: 행의 인덱스를 섞어라.
첫 번째 단계에서는 행의 인덱스를 섞는 과정이 필요하다. 여기서 Hash 함수라고 해서 이렇게 랜덤으로 순서를 섞는 것을 의미한다. 또는 해쉬함수는 이후에 Signature 행렬을 계산하게 되는데, 이것을 만들어 내는 전체 과정을 해쉬 함수라고 부르기도 한다. 그런데 여기서는 랜덤 섞음을 하는 것에 한정해서 이야기 하겠다.
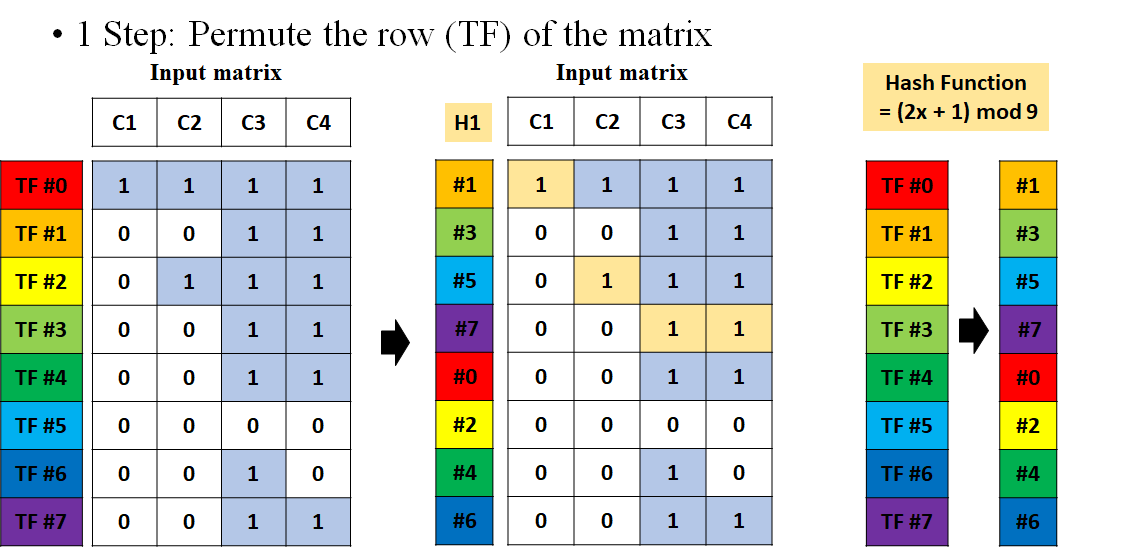
데이터 자체의 순서는 바꾸지 않고, 단지 인덱스의 순서만 바꾼다.
2 단계: 바뀐 인덱스를 순서대로 따라 가면서 1이 처음 등장하는 열을 체크 하고 이 때의 인덱스를 Signature 행렬의 값으로 할당한다.
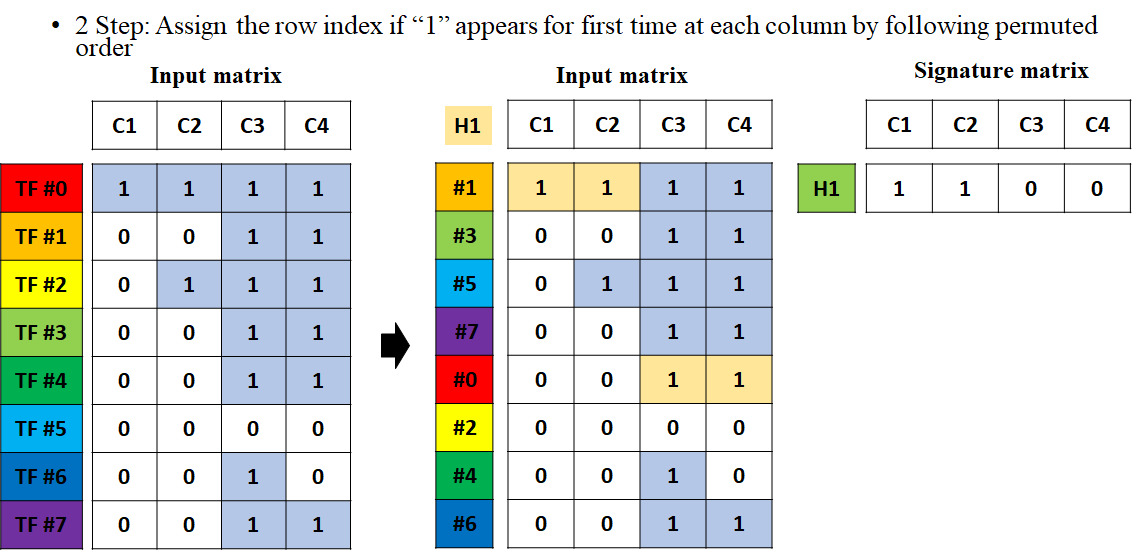
이건 무슨말인가 하면, 앞서 해쉬 함수로 바뀐 행의 인덱스를 순서대로 따라가보자. 즉, 0번째 행을 먼저 쳐다 보면 거기서 1이 처음 등장한 열을 찾아 보자. C3과 C4에서 1이 각각 처음 등장한다. 그리고 나머지는 0이므로, 무시한다. 일단 색깔을 칠해서 할당되었음을 표시해두자. 그리고는 1번째 행으로 가보자.
그러면 모든 열의 값이 1이라는 것을 볼 수 있다. 하지만 C3과 C4에 있는 1은 이미 0번째 행에서 할당하였으므로, 무시한다. 따라서, C1과 C2의 열의 값들만 할당되었다고 칠해준다. 이러한 과정을 통해서 모든 열에 대해서 색칠이 되면 그때 색칠된 1이 몇 번 행에 의해서 색칠되었는지 확인한다. 즉, C1과 C2의 색칠된 1은 첫 번째 행으로부터 할당되었으니, 1 1이 되고, C3과 C4의 색칠된 1은 0번째 행에 의해서 할당되었으니 0 0 이 되어서 결국 1 1 0 0 이라는 Signature 행렬이 완성된다.
3 단계: 위의 과정을 반복해서 원하는 개수의 해쉬 함수만큼 Signature 행렬을 확장시킨다.

랜덤으로 섞는 과정을 다시 수행해서 다르게 섞인 행의 인덱스를 만들자. 그리고는 앞에서 했던 것과 동일한 방식으로 다시 Signature 행렬의 행을 추가해보자. 이런식으로 원하는 개수만큼 해쉬 함수를 사용해서 아래와 같이 계속 Signature 행렬을 업데이트 시키면 된다.
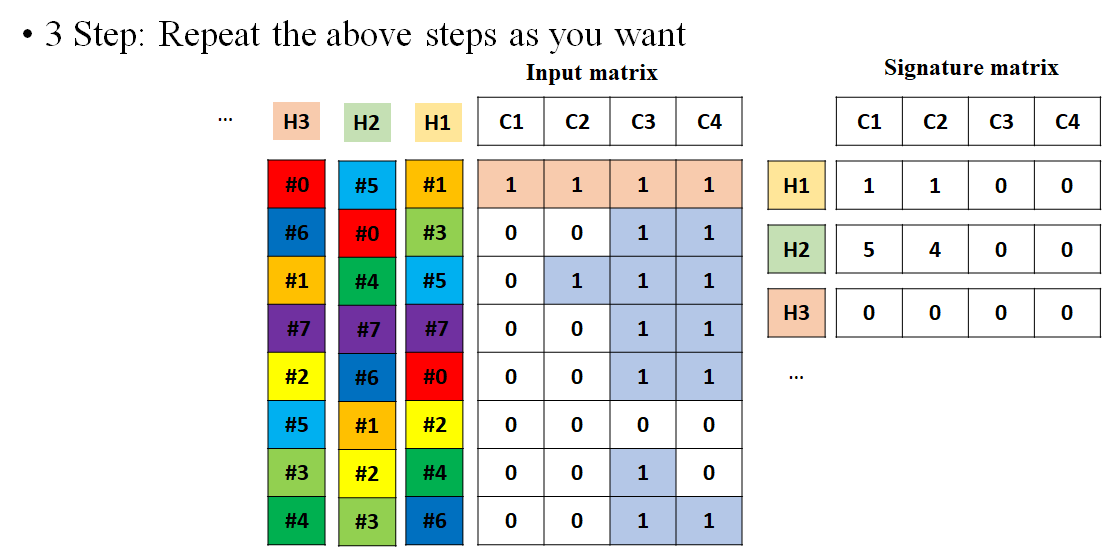
4 단계: 줄어든 차원을 가진 Signature 행렬을 Input 행렬의 축소판으로 생각하고 축소된 행렬에서 클러스터링을 한다. 그러면 그 결과는 인풋 행렬과 비슷하다.

줄어든 차원에서 클러스터링을 해보면 C3와 C4가 같다는 것을 알 수 있다. 그런데 실제 인풋 데이터에서도 C3과 C4는 비슷하다는 것을 알 수 있다. 물론 약간의 차이는 있어서 완전히 똑같다고는 할 수 없지만, 거의 비슷하다는 것을 유추해볼 수 있다. 이러한 약간의 차이를 줄이고자 한다면 계속 해쉬 함수를 늘려서 해보면 결국 인풋과 정확히 같아 질 수 있다.
하지만 여기에는 Trade-off가 존재한다. 너무 많이 signature 행렬을 늘리게 되면 계산시간이 결국 인풋 시간 만큼 걸릴 수 있고, 그러면 Min-hashing을 해야 하는 이유가 없어 진다. 그래서 어느 정도 정확성이 나오면 거기서 만족하고 계산하는게 이 암호화 방법을 사용하는 방법이겠다.
이번 포스팅에서는 간단하게 Min-hashing 알고리즘이라는 데이터 마이닝에서 암호화 방법에 대해서 알아보았는데, 이후 포스팅에서는 여기서 확장된 개념으로 LSH(Locality-Sensitive Hashing) 알고리즘에 대해서 알아보겠다.
반응형'인공지능 > 데이터 마이닝' 카테고리의 다른 글
[데이터 마이닝] Locality-Sensitive Hashing (LSH) 란? (1) 2021.02.07